robots协议是什么?

robots协议英文全称“Robots Exclusion Protocol”,也称为robots.txt文件或爬虫协议,是一种网站和网络爬虫之间的协议标准,是一个文本文件,通常放在网站服务器的根目录下,文件名为robots.txt,该文件用于指导网络搜索引擎和其他网络爬虫如何索引和爬取网站的内容。在robots协议中,网站管理员可以声明哪些URL是可以被爬虫抓取的,哪些是不应该被访问或抓取的。
robots协议是什么:
robots协议是一种网站与网络爬虫之间的协议,用于规范机器人如何抓取网站、访问和索引内容以及向用户提供内容,告诉搜索引擎哪些页面应该被抓取,哪些页面不应该被抓取。robots协议文件应位于您网站的根目录中,例如,如果您的网站名为xxx.com,则robots协议应位于domain.com/robots.txt。robots协议没有强制执行力,搜索引擎完全可以忽视robots.txt文件去抓取网页。
robots协议怎么看:
在浏览器地址栏中输入网站域名后加上/robots.txt。例如,如果您想查看aaa.com网站的robots协议,您应该访问https://aaa.com/robots.txt;
浏览器会加载该网站公开提供的robots协议文件内容。在这个文件中,您会看到一系列简单的指令;
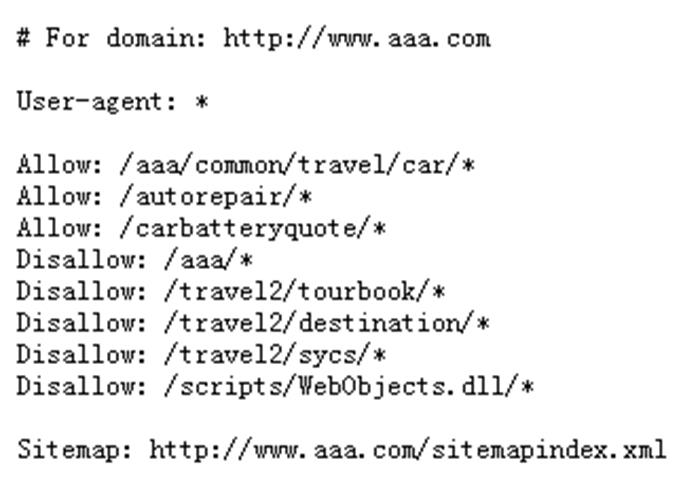
robots协议怎么写:
1、基本结构和命令
User-agent:定义这一行及后续行规则适用的搜索引擎爬虫,可以指定具体的爬虫名称,也可以使用通配符*代表所有爬虫。
Disallow:指示不想让爬虫访问的URL路径,URL路径必须相对于网站根目录,以正斜杠"/"开头。
Allow:明确指出允许爬虫访问的特定URL路径,当在一个已经Disallowed的父目录下指定了Allow,则爬虫将忽略父目录的Disallow规则。
Sitemap:告知爬虫网站地图的位置,以便更有效地抓取网站。
2、允许robots协议抓取指令
User-agent: *
Allow: /
3、禁止robots协议抓取指令
User-agent: *
Disallow: /
4、爬行延迟指令
User-agent: *
Crawl-delay: 10
robots协议作用:
1、优化抓取预算
抓取预算是指搜索引擎在您的网站上抓取的页面数量,该数量可能会根据您网站的大小、运行状况和反向链接数量而有所不同。如果您网站的页面数量超出了网站的抓取预算,则您的网站上可能存在未编入索引的页面。通过设置robots协议,可以减少搜索引擎对不必要的、低质量内容或动态生成链接的抓取,从而节约搜索引擎服务器资源,提高对网站重要页面的抓取频率和效率。
2、指引搜索引擎抓取
利用robots协议文件告知搜索引擎哪些网页或目录是可以被索引和抓取的,哪些是禁止抓取的,对于指引搜索引擎收录的内容非常有用,比如可以避免搜索引擎收录后台管理页面、重复内容、测试页面等非必要展示给公众的内容。
3、保护隐私信息
robots协议可以阻止正常运作的搜索引擎爬虫抓取含敏感信息或个人隐私的页面,减少这些信息意外出现在搜索引擎结果中的风险。
4、避免负载过高
对于大型网站或服务器性能有限的情况,通过robots协议可以暂时或永久性禁止爬虫抓取一些消耗大量服务器资源或带宽的页面,避免因爬虫频繁抓取而导致服务器过载。

